AlexNet VGGNet ResNet 对比 简介 |
您所在的位置:网站首页 › vgg16 resnet18 › AlexNet VGGNet ResNet 对比 简介 |
AlexNet VGGNet ResNet 对比 简介
|
AlexNet网络结构多GPUReluDropout层叠池化图片的随机采样其他
VGGNet网络结构3*3 卷积核1*1 卷积核LRN其他
ResNet退化问题残差学习残差网络子结构网络结构
reference
AlexNet
网络结构
结构图中可以看到模型分为了上下两部分, 两部分分别用一个GPU来运算, 可以提高运行速度, 因此也可以增大网络的规模 Relu数学表达 f ( x ) = m a x ( 0 , x ) f(x) = max(0, x) f(x)=max(0,x) 使用 Relu 训练速度更快 Dropout
工作原理: 每次 Dropout 都相当于训练一个原来的网络的子网络, 最后的结果相当于很多子网络的组合, 所以训练的效果会好些模型的泛化能力差的原因在于神经元记住了训练的样本, 要记住样本的特征显然需要多个神经元, 而 Dropout 是随机选择神经元的, 能够消除神经元之间的依赖关系, 增强泛化能力Dropout 也相当于数据增强 层叠池化AlexNet 中使用的是 Overlapping Max Pooling, 池化的窗口每次移动的步长小于它的长度 AlexNet 使用的是 3 * 3 的正方形, 每次移动步长为 2, 重叠池化可以避免过拟合 但其实也可以用步长较大的卷积层代替 图片的随机采样图片的原大小是[256, 256], 但是输入图片的大小为[224, 224], 每次只输入图像的一部分, 每次取原来图像的一部分, 相当于换了一个角度看图片, 也相当于增加了训练的数据(数据增强), 训练出来的模型泛化能力会更强 其他 SGD momentum = 0.9 动量梯度下降Batch size = 128Learning rate = 0.01, 每训练一定次数, 学习率缩小10倍训练读多个CNN模型, 然后做投票ensemble VGGNetVery Deep Convolutional Networks 网络结构
如图所示, 2层的 3*3 卷积核可以替代1层的 5*5 卷积核 (步长为1) 两种方式的视野域是一样的, 输入输出格式都不变2层比1层多一次非线性变化, 网络深度增加也能够保证学习更复杂的模式采用堆积的小卷积核还可以减少参数数目, 还是拿上图举例(一个绿色方形代表一个参数), 假定输入输出通道数都是 C C C, 那么两层结构的参数数目为 2*3*3* C 2 C^2 C2, 单层结构的参数数目是 5*5* C 2 C^2 C2, 多了28%的数目如果上面两张图不能理解可以结合一下这张神图 (左边一列表示输入, 通道数3, 中间两列就是参数, 两个神经元, 右边是输出, 通道数2, 总共3*3*3*2个参数)
局部归一化, 把相邻的几个通道进行归一化 快过时了 其他 多尺度输入: AlexNet中也有用到(就是从不同的角度看图片), VGGNet做的更极端, 它随机使用不同的尺度缩放训练多个分类器, 然后做ensemble ResNetResidual Network 退化问题
可能是因为网络越深, 参数越多, 优化也就更难 ResNet的提出就是为了解决这种退化问题 残差学习
H ( x ) − x H(x)-x H(x)−x对 x x x求偏导后会有一个恒等项1, 使用链式法则求导时, 残差网络子结构
下图为VGG-19, 34层的普通卷积神经网络, 34层的ResNet网络的对比图
|

 每一运算都会随机地将一些神经元置为 0 Dropout 用在了全连接层上, 因为全连接层的参数较多(4096 * 4096), 容易过拟合 AlexNet 中设置的 Dropout = 0.5
每一运算都会随机地将一些神经元置为 0 Dropout 用在了全连接层上, 因为全连接层的参数较多(4096 * 4096), 容易过拟合 AlexNet 中设置的 Dropout = 0.5


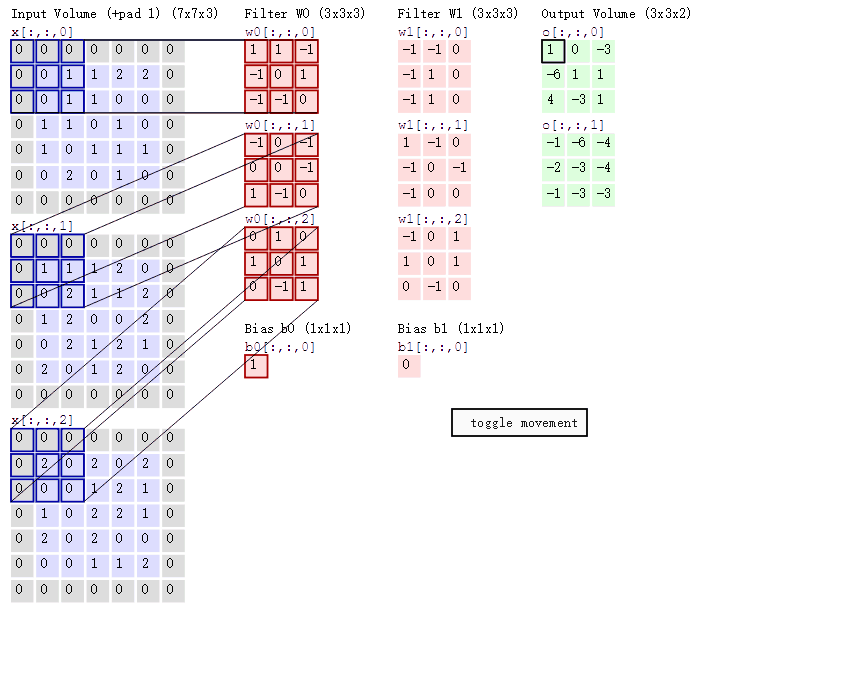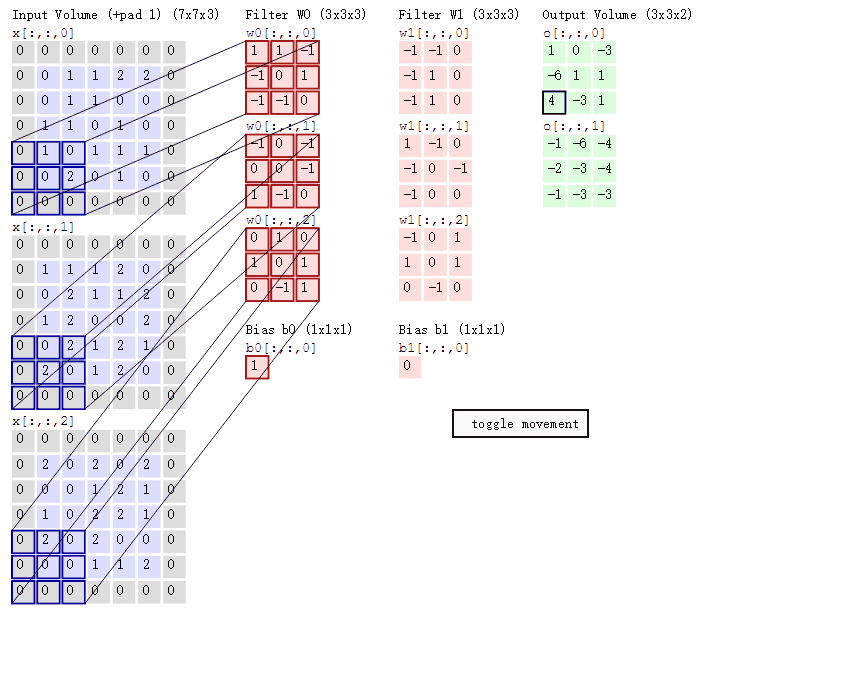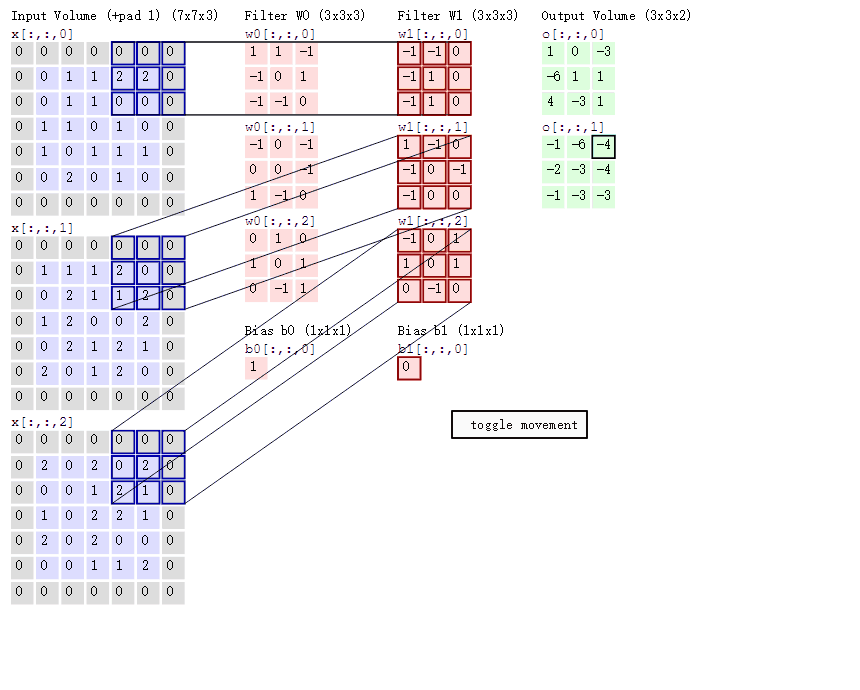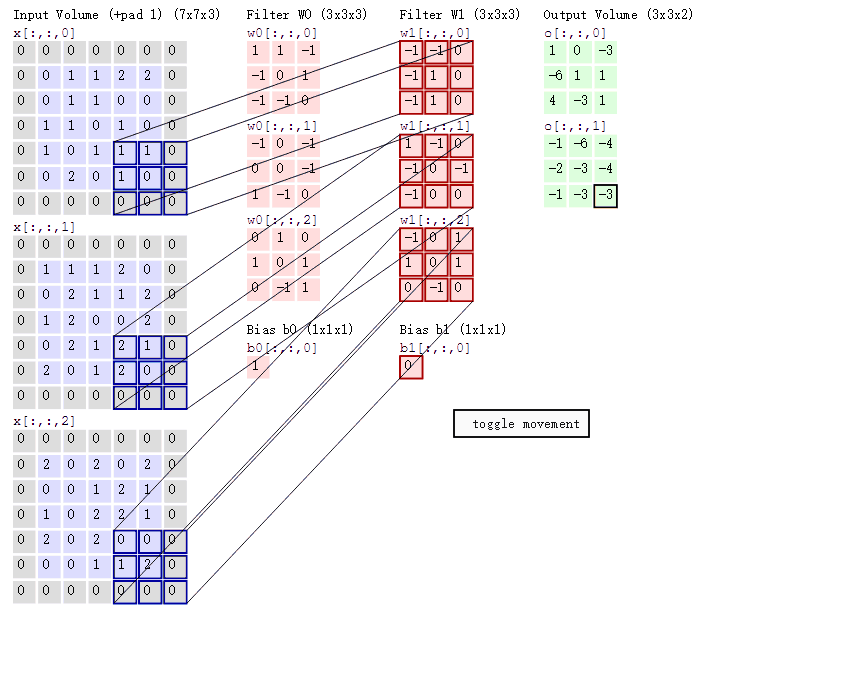

 VGGNet中我们可以看出深度对于神经网络的重要性, 但从图中可以看出网络深度达到一定程度时, 深层网络的总体表现不如浅层网络, 这种现象称为退化问题(degradation problem) 为什么会这样? 如果是因为梯度消失, 梯度爆炸, 可以通过中间层标准化(batch normalization)等缓解 也不是过拟合造成的, 因为训练集上深层网络也不如浅层的
VGGNet中我们可以看出深度对于神经网络的重要性, 但从图中可以看出网络深度达到一定程度时, 深层网络的总体表现不如浅层网络, 这种现象称为退化问题(degradation problem) 为什么会这样? 如果是因为梯度消失, 梯度爆炸, 可以通过中间层标准化(batch normalization)等缓解 也不是过拟合造成的, 因为训练集上深层网络也不如浅层的



【本文地址】